これはRubyアドベントカレンダーとSmartHRアドベントカレンダーの17日目の記事です。
12/9 に nagano.rb で文字について発表して、同じのを 12/15 に SmartHR 社内で LT しました。
スライドはこちら
同じ文字?

この2つの文字は同じものに見えますか?
実はこれは同じ文字を異なるフォントで表示したものです。

ゴシック体と明朝体で字体が異なって見えるのと同じことなので、同じ文字と言えるでしょう。
コンピュータで扱う文字は文字ごとに番号(コードポイント)が振られていて、プログラムから見たときには同じコードポイントであれば同じ文字として扱われます。
Ruby で文字のコードポイントを得るには String#ord を使用できます。
'直'.ord.to_s(16) #=> "76f4"
'ほげ'.chars.map{_1.ord.to_s(16)} #=> ["307b", "3052"]
または String#unpack('U*') でも可能です。
'ほげ'.unpack('U*').map{_1.to_s(16)} #=> ["307b", "3052"]
正規化

この2つは同じ文字でしょうか。 同じに見えますが、これは異なるコードポイントの文字です。
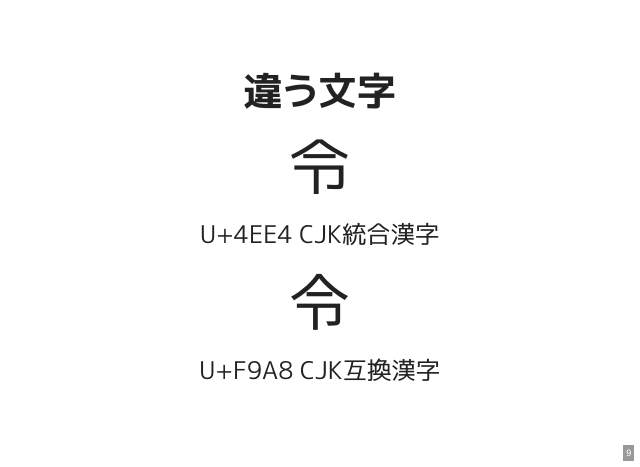
前者はCJK統合漢字、後者はCJK互換漢字というカテゴリに含まれています。
コードポイントが異なるので普通に比較したら不一致となりますが、
rei1 = '令' rei2 = '令' rei1.ord.to_s(16) #=> "4ee4" rei2.ord.to_s(16) #=> "f9a8" rei1 == rei2 #=> false
CJK互換漢字を String#unicode_normalize で正規化すると統合漢字に変換されます。
rei1 == rei2.unicode_normalize #=> true
ユニコードの正規化は UAX #15: Unicode Normalization Forms に仕様があります。
String#unicode_normalize のデフォルトは NFC ですが、NFKC を使うと次のような変換もできます。
'0'.unicode_normalize(:nfkc) #=> '0' '①'.unicode_normalize(:nfkc) #=> '1' 'ア'.unicode_normalize(:nfkc) #=> 'ア' 'パ'.unicode_normalize(:nfkc) #=> 'パ' '㌖'.unicode_normalize(:nfkc) #=> 'キロメートル'
異体字セレクタ

これは同じ文字でしょうか?
日本語に詳しければ、これは字体が異なるだけで同じ文字だということはわかるでしょう。 最初の「直」と同じです。
ですが、ここでは異体字セレクタを使った例を示します。

U+E0100〜U+E01EF が異体字セレクタです。上の例では U+E0102 です。
基底文字に異体字セレクタを追加することで文字の見た目を指定することができます。 プレーンテキストでも字体を指定できる仕組みです。
ただしちゃんと表示するには、システムとフォントが対応している必要があります。
どのような異体字があるか調べるには 異体字セレクタセレクタ が便利です。
たとえば「邊」の一覧は https://747.github.io/vsselector/#!/ja/908a で見れます。 最初に示した「直」の異体字セレクタもあります。https://747.github.io/vsselector/#!/ja/76f4
異体字セレクタは unicode_normalize では消えません。消したい場合は gsub とかで消しましょう。
str.gsub(/[\u{e0100}-\u{e01ef}]/, '')
「髙」
「髙」は俗に「はしご高」と呼ばれてる文字です。
Unicode では「髙」は「高」の異体字ではなく別の文字です。別の文字なので正規化の対象ではないし、異体字セレクタにもありません。
SJIS(Windows-31J)にも存在する文字です。なので変換も可能です。
'髙'.encode('Windows-31J')
#=> "\x{FBFC}"
'髙'.encode('SJIS') # SJIS は Windows-31J の別名
#=> "\x{FBFC}"
でも JIS では「髙」という文字は存在しなくて「高」の異体字扱いです。対応する文字がないので変換できません。
Ruby では SJIS と Shift_JIS は異なるエンコーディングなので注意。
'髙'.encode('Shift_JIS') # Shift_JIS と SJIS は異なる
# `encode': U+9AD9 from UTF-8 to Shift_JIS
# (Encoding::UndefinedConversionError)
「髙」は「高」と別の文字として扱う分には何も問題ないんですが、人名検索とかで「高」と同一文字として扱いたいこともあるかもしれないのでむずかしいところです。
「﨑」
「﨑」は俗に「たち崎」と呼ばれてる文字です。
これは「令」と同じく CJK互換漢字に含まれる文字です。
けど、「令」と異なり unicode_normalize では「崎」にはなりません。
'﨑'.unicode_normalize #=> "﨑"
同じくCJK互換漢字に含まれてる「福」はちゃんと「福」に変換されます。
'福'.unicode_normalize #=> "福"
「﨑」は何が違うかというとこういうことでした。
なお、U+FA11(﨑)はU+5D0E(崎)、U+FA14(﨔)はU+6B05(欅)およびU+6989(榉)、U+FA1F(﨟)はU+81C8(臈)にそれぞれ統合漢字ブロックの異体字を持つが、字体差が大きいとみなされ統合の範疇とされていない。
これも「髙」と同じく正規化するには個別でやる必要がありそうです。
おまけ

平仮名の「へ」と片仮名の「ヘ」がまったく同じ字体なのは日本語のバグですね。
文字数

1文字に見えるこれらの絵文字は実際には何文字でしょう?
国旗は2文字で構成されてます。
'🇯🇵'.size #=> 2
日本の国コードは JP ですが国旗用文字の「🇯」と「🇵」をつなげて書くと「🇯🇵」となります。 同様に「🇺」と「🇸」をつなげると「🇺🇸」になります。
3人家族の絵文字はコードポイント U+1F46A の1文字です。
'👪'.size #=> 1
ところが子供が一人増えて4人家族になるとコードポイント7文字で構成されます。
'👨👩👧👦'.size #=> 7
絵文字以外にも、たとえば濁点付きのかな文字は、「ぱ」のように1文字の濁点付き文字と、「は」と「◌゚」の2文字を合成した文字があります。

人間に肌色や髪型を合成した絵文字もあります。

書記素
プログラム的に自然なのはコードポイントの数ですが、人には不自然です。
人に自然な文字の単位に「書記素」というのがあります。
書記素(しょきそ、英: grapheme)とは、書記言語において意味上の区別を可能にする最小の図形単位をいう
Ruby では String#grapheme_clusters を使うと文字列を書記素に分割できます。
'🇯🇵👪👨👩👧👦'.size #=> 10
'🇯🇵👪👨👩👧👦'.grapheme_clusters #=> ["🇯🇵", "👪", "👨👩👧👦"]
'🇯🇵👪👨👩👧👦'.grapheme_clusters.size #=> 3また、正規表現の \X は書記素1文字に適合します。
'🇯🇵👪👨👩👧👦'.scan(/./)
#=> ["🇯", "🇵", "👪", "👨", "", "👩", "", "👧", "", "👦"]
'🇯🇵👪👨👩👧👦'.scan(/\X/)
#=> ["🇯🇵", "👪", "👨👩👧👦"]まとめ
ユニコードは結構カオス。
文字列を比較するときは正規化した方がいいかもしれない。
文字数を数えるときはコードポイントなのか書記素なのかを考えた方がいいかも。