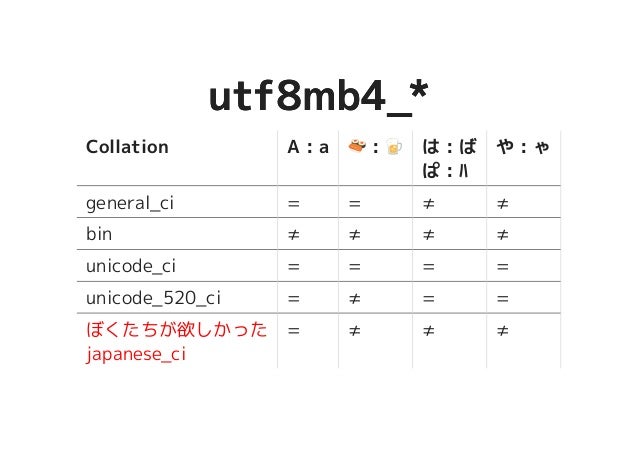
MySQL 5.7.12 で突如登場した MySQL Shell とか X DevAPI とか X Protocol とかが面白そうだったので調べてみました。
Document Store とかも同じ文脈で語られてて、それぞれの用語が何を表してるのかややこしかったので、まずその辺から。
X Protocol
mysqlx プラグインを使用することで追加されるサーバー/クライアントプロトコル。ポート番号は 33060。
詳細→ https://dev.mysql.com/doc/internals/en/x-protocol.html
X DevAPI
各プログラミング言語用の新しいAPI。Document Store用のAPIも含む。今のところ、MySQL Shell JavaScript, MySQL Shell Python, Java, .Net, Node.js 用の API がある。X Protocol を使用。
詳細→ https://dev.mysql.com/doc/x-devapi-userguide/en/
MySQL Shell
X DevAPI が組み込まれた JavaScript / Python の対話型コマンドラインツール。
詳細→ https://dev.mysql.com/doc/refman/5.7/en/mysql-shell.html
Document Store
MySQLをドキュメントデータベースとして使う方法。
内部的には、JSON型の doc という名前の1カラムだけを持つテーブル(実際には _id という自動生成カラムもある)を作って、すべてのデータをJSONで突っ込むことでドキュメントデータベースとして使用している。
詳細→ https://dev.mysql.com/doc/refman/5.7/en/document-store.html
ということで MySQL Shell を使ってみます。
MySQL 5.7.12 のインストール
自分は Xubuntu を使っていて apt-get で MySQL をインストールすると 5.7.12 が入るので、お手軽だと思ったんですけど、これは mysqlx プラグインを含んでいないため使えませんでした。ここ http://dev.mysql.com/downloads/mysql/ から適当にインストールします。
個人的に MySQL の rpm や deb パッケージは信用してないので(my.cnf を /usr に置いたりする)、tarball からインストールします。
# cd /usr/local
# tar xf /tmp/mysql-5.7.12-linux-glibc2.5-x86_64.tar.gz
# ln -s mysql-5.7.12-linux-glibc2.5-x86_64 mysql
# cd mysql
# ./bin/mysqld --no-defaults --initialize
...
2016-05-10T02:24:00.559906Z 1 [Note] A temporary password is generated for root@localhost: krJ&LWZFv3:Q
# chown -R mysql:mysql .
# ./bin/mysqld --no-defaults --user=mysql --log-error=/tmp/mysql.err --daemonize >> /tmp/mysql.err 2>&1
mysqld --initialize の最後の行にパスワードが表示されるのでメモっときます。
いちいち --no-defaults をつけてるのは、Ubuntu の MySQL の設定を読まないようにするためです。
本当はちゃんと my.cnf を書けばいいんですけど、お試しなのでこのままで。
% mysql -uroot -p
Enter password: krJ&LWZFv3:Q
mysql>
この状態で何かクエリを実行しようとすると、
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
って怒られるので、ぶつぶつ言いながらパスワードを設定します。
mysql> set password = 'abcdefg';
テスト用のデータベースを作成し、mysqlx プラグインを有効にしておきます。
mysql> create database test;
mysql> install plugin mysqlx soname 'mysqlx.so';
MySQL Shell のインストール
MySQL Shell は http://dev.mysql.com/downloads/shell/ から持ってきます。
残念ながらバイナリ tarball は無いみたいなので、deb をダウンロードして入れました。
# dpkg -i mysql-shell_1.0.3-1ubuntu15.10_amd64.deb
MySQL Shell を使う
コマンド名は mysqlsh です。
% mysqlsh --sql --js --user=root test
Creating an X Session to root@localhost:33060
Enter password:
...
mysql-js>
URI形式でも接続できます。
% mysqlsh --sql --js --uri root@localhost/test
コマンドラインでパスワードを指定することもできます。
% mysqlsh --sql --js --user=root --password=abcdefg test
% mysqlsh --sql --js --uri root:abcdefg@localhost/test
「--sql」がないと、後で出てくる「session.sql()」が何故か使えないので指定しています。
起動後は対話型 JavaScript として動きます。何故か日本語は入力できませんでした。
mysql-js> function fib(n) { if (n < 2) return n; else return fib(n-1) + fib(n-2); }
mysql-js> fib(10)
55
複数行でも記述できます。「...」に対して何も入力せずに改行すると複数行入力の終了とみなされます。
mysql-js> function fib(n) {
... if (n < 2)
... return n;
... else
... return fib(n-1) + fib(n-2);
... }
...
mysql-js> fib(10)
55
session, db という変数が接続とデータベースを表しているようです。
mysql-js> session
<NodeSession:root@localhost:33060/test>
mysql-js> db
<Schema:test>
普通にSQLとして使ってみます。
mysql-js> session.sql("CREATE TABLE hoge (id INT, str VARCHAR(32))")
mysql-js> db.tables
{
"hoge": <Table:hoge>
}
mysql-js> db.hoge.insert(['id', 'str']).values(123, 'abc')
Query OK, 1 item affected (0.06 sec)
mysql-js> db.hoge.insert(['id', 'str']).values(456, 'def').values(789, 'ghi')
Query OK, 2 items affected (0.05 sec)
mysql-js> db.hoge.select(['id', 'str'])
+-----+-----+
| id | str |
+-----+-----+
| 123 | abc |
| 456 | def |
| 789 | ghi |
+-----+-----+
3 rows in set (0.00 sec)
mysql-js> db.hoge.select(['id', 'str']).where('id=456')
+-----+-----+
| id | str |
+-----+-----+
| 456 | def |
+-----+-----+
1 row in set (0.01 sec)
mysql-js> db.hoge.update().set('str', 'hoge').where('id = 456')
Query OK, 1 item affected (0.06 sec)
mysql-js> db.hoge.select(['id', 'str'])
+-----+------+
| id | str |
+-----+------+
| 123 | abc |
| 456 | hoge |
| 789 | ghi |
+-----+------+
3 rows in set (0.00 sec)
mysql-js> db.hoge.delete().where('id=456');
Query OK, 1 item affected (0.04 sec)
mysql-js> db.hoge.select(['id', 'str'])
+-----+-----+
| id | str |
+-----+-----+
| 123 | abc |
| 789 | ghi |
+-----+-----+
2 rows in set (0.00 sec)
mysql-js> db.hoge.delete()
Query OK, 2 items affected (0.03 sec)
mysql-js> db.hoge.select(['id', 'str'])
Empty set (0.00 sec)
Document Store として使ってみます。
ドキュメントを格納するテーブルは Collection となり普通のテーブルとしては扱われません。
mysql-js> db.createCollection('fuga')
<Collection:fuga>
mysql-js> db.tables
{
"hoge": <Table:hoge>
}
mysql-js> db.collections
{
"fuga": <Collection:fuga>
}
実体は普通にテーブルです。_id は生成カラムなので、実質 JSON の doc カラムひとつだけのテーブルです。
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| fuga |
| hoge |
+----------------+
2 rows in set (0.00 sec)
mysql> show create table fuga\G
*************************** 1. row ***************************
Table: fuga
Create Table: CREATE TABLE `fuga` (
`doc` json DEFAULT NULL,
`_id` varchar(32) GENERATED ALWAYS AS (json_unquote(json_extract(`doc`,'$._id'))) STORED NOT NULL,
UNIQUE KEY `_id` (`_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
どうやらテーブル構造がポイントらしく、hoge テーブルに同じ型の doc と _id カラムを追加すると、Collection として扱われます。
mysql> ALTER TABLE hoge ADD doc json,
-> add _id varchar(32) GENERATED ALWAYS AS (json_unquote(json_extract(`doc`,'$._id')))
-> STORED NOT NULL UNIQUE;
テーブル構造はキャッシュされてるようなので、再接続してから確認します。
mysql-js> \connect root:abcdefg@localhost/test
Closing old connection...
Creating an X Session to root@localhost:33060/test
Default schema `test` accessible through db.
mysql-js> db.tables
{
}
mysql-js> db.collections
{
"fuga": <Collection:fuga>,
"hoge": <Collection:hoge>
}
mysql-js>
Collection として使ってみます。
mysql-js> db.fuga.add({abc: 123})
Query OK, 1 item affected (0.05 sec)
mysql-js> db.fuga.add([{name: 'tmtms'}, {text: 'AIUEO'}])
Query OK, 2 items affected (0.04 sec)
mysql-js> db.fuga.find()
[
{
"_id": "682d6ac3b616e6111432022c3a710274",
"name": "tmtms"
},
{
"_id": "a0478da8b616e6111432022c3a710274",
"abc": 123
},
{
"_id": "e82f6ac3b616e6111432022c3a710274",
"text": "AIUEO"
}
]
3 documents in set (0.00 sec)
mysql-js> db.fuga.find('abc=123')
[
{
"_id": "a0478da8b616e6111432022c3a710274",
"abc": 123
}
]
1 document in set (0.00 sec)
mysql-js> db.fuga.modify('abc=123').set('xyz', 789)
Query OK, 1 item affected (0.06 sec)
mysql-js> db.fuga.find('abc=123')
[
{
"_id": "a0478da8b616e6111432022c3a710274",
"abc": 123,
"xyz": 789
}
]
1 document in set (0.00 sec)
mysql-js> db.fuga.modify('abc=123').unset('abc')
Query OK, 1 item affected (0.06 sec)
mysql-js> db.fuga.find('xyz=789')
[
{
"_id": "a0478da8b616e6111432022c3a710274",
"xyz": 789
}
]
1 document in set (0.00 sec)
mysql-js> db.fuga.remove('xyz=789')
Query OK, 1 item affected (0.06 sec)
mysql-js> db.fuga.find()
[
{
"_id": "682d6ac3b616e6111432022c3a710274",
"name": "tmtms"
},
{
"_id": "e82f6ac3b616e6111432022c3a710274",
"text": "AIUEO"
}
]
2 documents in set (0.01 sec)
おわりに
5.6 以降強化され続けている JSON 機能を使ってドキュメントデータベースのように使える API を用意し、そのためのプロトコルも作成したって感じでしょうか。
プロトコルはパイプライン処理ができるようになっていたりして、それ単体で見ても面白そうなので、そのうちちゃんと調べてみたいです。