4月にMySQLの日本語コレーションについて語り合う場に呼ばれていろいろ話を聞いてきました。すぐにブログを書こうと思ったんですが、はや2ヶ月経過…。
ときどき、自分がMySQLの文字コードに関して発表する際に、次のようなスライドをいれてるんですが、
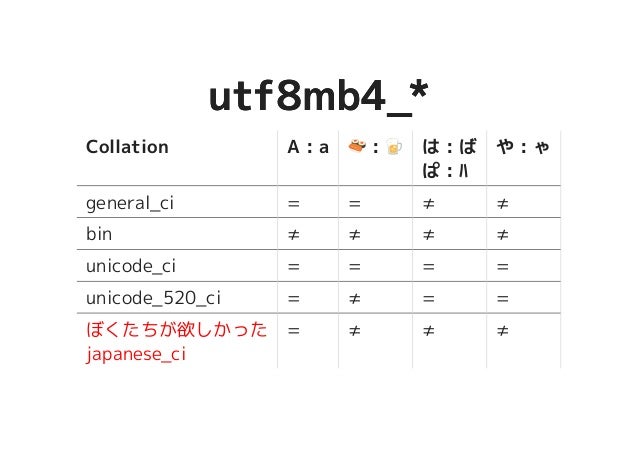
MySQL 8.0 でとうとう日本語コレーションが入ることになったのに、なんか期待してたのと違いました。

で、その辺の話を聞きました(2ヶ月も経ってるのでうろ覚え)。
Q. わざわざ日本語ロケール作るんだったら日本人が扱いやすいロケールにしてほしい
utf8mb4_ja_0900_as_csはMySQLが独自に考えたものではない。Unicode規格に従っている。過去にいろいろ独自にやって失敗してきてるので、もう独自にやるのは避けたい。ai(accent insensitive)で「ハ」=「パ」=「バ」になるのも、ci(case insensitive)で「や」=「ゃ」になるのもUnicodeに従っている。
Q. ja_0900_as_cs は 0900_as_cs と何が違うの?
utf8mb4_ja_0900_as_csは日本語固有の規則に従う。CLDR参照。長音記号「ー」の順序が前の字によって異なる。たとえば「アー」は「アイ」よりも前だが「ウー」は「ウイ」よりも後。
そんな凝ったことしてたのか…。
その他
コレーションは xml ファイルを置くことで独自に定義できるので、標準のコレーションが気に入らないのなら自分で定義すればいい。
マルチバイト文字はリコンパイルしないと組み込めないと思ってましたが、それは文字セットの話でコレーションについてはコンパイル不要とのことでした。
ちゃんとマニュアルにも書いてありました。10.4.4 Unicode 文字セットへの UCA 照合順序の追加
ja_0900_as_csはひらがなとカタカナを区別しないが、区別したい場合のためにja_0900_as_cs_ksというコレーションを作ろうとしている。
うーん、個人的にはそこまで区別したいんだったら utf8mb4_bin でいいかな…。
MySQLは標準(Unicode)に従ってるだけなので、独自におかしなことをしているわけではないということでした。
そしてUnicodeの日本語の照合順序はJIS X 4061が元なので、日本語の扱いがおかしいと日本人がMySQLに対して言うのは「お前がゆーな!」状態でした。申し訳ありませんでした!
あと最近知ったのですが、ja_0900_as_cs の場合は、漢字の順番もちゃんとJIS順になってました。
試してみると、UTF-8の文字コード順ではなくJISコード順(音読みの順)になっていることがわかります。
mysql> select hex(s),s from ja_0900_as_cs order by s; +--------+------+ | hex(s) | s | +--------+------+ | E4BA9C | 亜 | | E4BC8A | 伊 | | E99BA8 | 雨 | | E6A084 | 栄 | | E5A5A5 | 奥 | +--------+------+
業界によっては実は結構嬉しいのかもしれません。